

Inspiracją do napisania wpisu o tajnikach interpretacji analizy treści była potencjalna współpraca z nowym podwykonawcą oraz korespondencja z nim. Problematyka związana z analizą treści nie jest nowym tematem. Naszą branżę charakteryzuje fakt, że sposób patrzenia na wartości liczbowe zależy od osoby, która im się przygląda. Tym samym jedna konkretna wartość liczbowa jest interpretowana przez różnych aktorów w całkowicie odmienny sposób. Ci aktorzy to klient, tłumacz oraz biuro tłumaczeń.
Niczym oczekiwanie badacza analizującego naturę światła, od którego to oczekiwania zależy czy światło będzie miało właściwości fali czy cząsteczki, w sektorze tłumaczeniowym wartość analityczna przybiera jedną z trzech dostępnych "form". Przyjrzyjmy się temu zaskakująco dziwnemu zjawisku z bliska.
Skąd się biorą analizy treści?
Tytułem wstępu należy krótko wyjaśnić, że w dzisiejszych czasach - wbrew wyobrażeniom wielu osób niezwiązanych z przemysłem tłumaczeniowym - zawodowi tłumacze nie wystukują przetłumaczonej treści na tradycyjnej maszynie do pisania. Co do zasady profesjonalni tłumacze w procesie przekładu nie korzystają również z edytorów tekstu (np. MS Word czy Google Docs).
O ile różnica w pracy i efektywności między tradycyjną maszyną do pisania a programami do tworzenia i edycji dokumentów jest gigantyczna, to przepaść między tymi drugimi, a narzędziami wykorzystywanymi w dzisiejszych czasach na szeroką skalę przez przemysł tłumaczeniowy mierzona jest w latach świetlnych.
Mowa oczywiście o platformach wspierających procesy tłumaczeniowe, o których moje koleżanki oraz ja rozpisywaliśmy się wielokrotnie na tym blogu. Rzecz w tym, że rzeczone platformy poprawiają efektywność pracy zawodowego tłumacza, a przynajmniej takie jest założenie. Cały bajer polega na tym, że mają one wręcz nieograniczone możliwości zapamiętywania realizowanych przy ich pomocy tłumaczeń.
Aby umożliwić tłumaczowi wykorzystanie wcześniej wprowadzonych tłumaczeń, tego typu platformy muszą mieć możliwość analizy treści, które ktoś chce przetłumaczyć. Zasada działania jest bardzo prosta: treść dzielona jest na segmenty - dla uproszczenia przyjmijmy, że segment to jedno zdanie. Dzięki temu algorytm porównawczy jest w stanie porównać każdy jeden segment z każdym innym segmentem w obrębie jednego tekstu lub dokumentu czy w zakresie jednego zlecenia (kilku, kilkunastu czy wręcz kilkuset dokumentów o dowolnej objętości treści).
Analiza treści - repetitions
W opisany powyżej sposób obliczana jest między innymi ilość tzw. repetitions (powtórek). Łatwiej będzie zrozumieć czym są repetitions, gdy wyobrazimy sobie 20 sztuk ustandaryzowanych kart charakterystyki różnych substancji chemicznych. Na każdej z tych kart będzie cała rzesza identycznych, powtarzających się zwrotów takich jak:
- Identyfikator produktu,
- Nazwa handlowa,
- IDENTYFIKACJA ZAGROŻEŃ,
- Informacje uzupełniające,
- Inne zagrożenia,
- Brak danych,
- Nazwa substancji,
- Numer CAS,
- Numer WE.
Nie trudno się domyślić, że tłumacz nie musi 20 razy przekładać każdego z wyszczególnionych (oraz pozostałych powtarzających się zwrotów) z osobna, nawet jeżeli występują one w każdej z 20 kart charakterystyki.
Widać to bardzo dokładnie na poniższej przykładowej analizie.
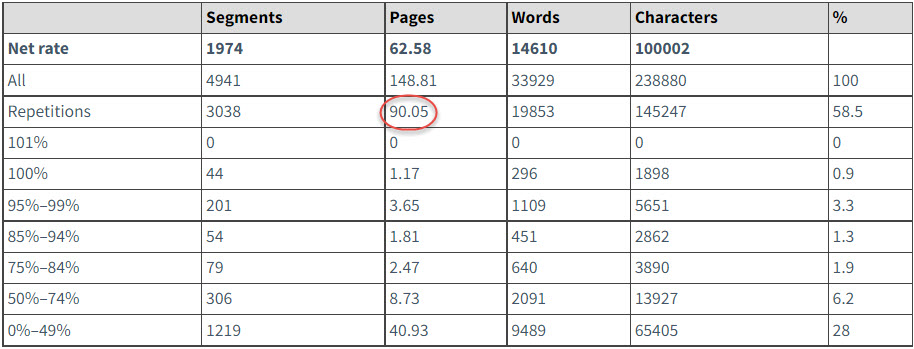
Choć nie ma w tym wszystkim filozofii, a wartość liczbowa jest wartością niepodważalna, to wciąż zdarzają się nieporozumienia co do jej interpretacji. Zaznaczona czerwonym kolorem wartość wynosząca 90,05 stron stanowi całkowitą objętość treści powtarzających się bez uwzględnienia pierwszego wystąpienia. Co to w praktyce oznacza?
Oznacza ni mniej ni więcej, że całkowity wysiłek wymagany na wprowadzenie tłumaczenia tych treści wykonuje algorytm. Na żadnym etapie opracowania przekładu czy wysiłku umysłowego tłumacza repetitions nie stanowią jakiegokolwiek obciążenia procesowego.
Możliwość ich izolacji przez oprogramowanie wręcz daje tłumaczowi czy korektorowi szerokie pole do popisu, gdyż w przypadku popełnienia błędu przy tłumaczeniu pierwszego wystąpienia danego segmentu, poprawić wystarczy wyłącznie pierwsze wystąpienie, a nie każdy segment z osobna.
Analiza treści - fuzzy matches
Omawiane analizy treści wykrywają nie tylko repetitions, którymi są w 100% identycznymi segmentami. W ramach analizy wykrywane są również różne stopnie podobieństwa - nie tylko między segmentami w obrębie treści wymagającej tłumaczenia, ale równie w kontekście wykonanych wcześniej tłumaczeń, które zostały zapisane w pamięci tłumaczeniowej. Zakresy podobieństwa (fuzzy matches) wyszczególniłem na poniższej ilustracji.
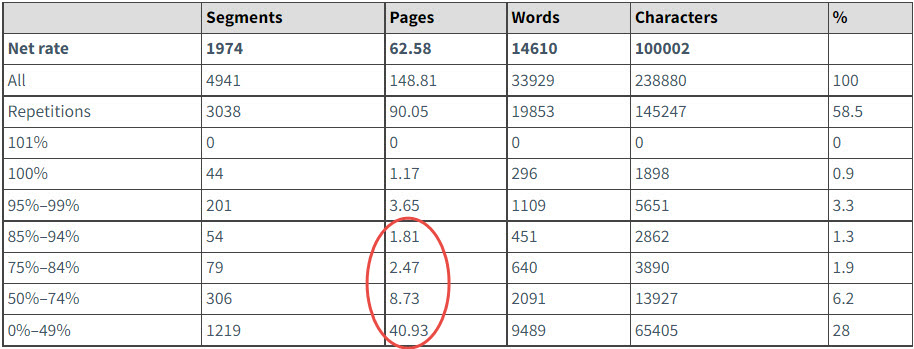
Zacznijmy od dołu - zakres podobieństwa między 0 a 49% to treści nowe (unikalne). Ich przekład wymaga uruchomienia procesów twórczych, podczas których tłumacz musi wykonać największy wysiłek umysłowy. Pomoc w postaci podpowiedzi z pamięci tłumaczeniowej nie na wiele się zda przy podobieństwie na tym poziomie.
Przy kolejnych zakresach, czyli 50-74%, 75-84%, 85-94%, można stwierdzić, że tłumacz w mniejszym lub większym stopniu posiłkuje się podpowiedziami z pamięci tłumaczeniowej, przy czym im wyższy stopień podobieństwa, tym mniejszy wysiłek oraz krótszy czas potrzebny na opracowanie tłumaczenia.
Cała ta "aparatura" ma jedno na celu, a mianowicie redukcję nakładów związanych z wykonywaniem tłumaczeń. W efekcie końcowym otrzymujemy optymalne koszty tłumaczeń, skrócone czasy dostaw oraz wyższy współczynnik spójności treści.
Oczywiście powyższy opis jest mocno uproszczony. Moim celem było jedynie przedstawienie ogólnej zasady działania oprogramowania CAT, aby móc odnieść się do analiz treści. Wspomniane platformy oferują szereg funkcjonalności przydatnych w codziennej pracy biura tłumaczeń czy tłumacza freelancera.
Niemniej jednak sądzę, że z tego spłyconego opisu skorzystają nie tylko osoby spoza branży tłumaczeniowej, hobbistyczni wieczorowi tłumacze (jak ten słynny hydraulik, który po pracy przekłada na polski dzieła Goethego), początkowi tłumacze, ale również starzy branżowi wyjadacze.
Trzy oblicza jednej wartości liczbowej
Czym zatem jest ta jedna wartość liczbowa, której interpretacja sprawie problemy? Jest nią oczywiście objętość rozliczeniowa i nie interpretacja jest problemem, a jedynie fakt, że każda ze wspomnianych stron próbuje ugrać jak najlepsze warunki realizacji zlecenia - co jest oczywiście zrozumiałe.
Klient jak najniższy koszt tłumaczenia pisemnego. Tłumacz możliwie najwyższe wynagrodzenie, a biuro tłumaczeń otrzymać prowizję za wykonaną pracę, która wbrew pozorom nie polega jedynie na przesyłaniu maili od klienta do tłumaczy (o czym możesz poczytać we wpisie zatytułowanym Zakładamy biuro tłumaczeń).
Analiza treści oczami klienta
Dla klientów najoszczędniej byłoby, gdyby ponoszone z tytułu usług tłumaczeniowych koszty nie obejmowały treści powtarzających się (repetitions oraz 101/100 match). Wielokrotnie jestem pytany przez zleceniodawców o to, dlaczego muszą płacić za powtarzające się ciągle treści. Moja odpowiedź zawsze obejmuje dwa wątki.
Po pierwsze to nie od nas zależy, co nam dany zleceniodawca wysyła do tłumaczenia. Mamy też takich klientów, którzy we własnym zakresie "zarządzają" swoimi tłumaczeniami i wysyłają nam wyłącznie treści unikalne (no match). Pewnie wypracowali jakieś sposoby składania i potrafią (lub nie) się w tym wszystkim połapać. Jest to najbardziej oszczędne rozwiązanie w punktu widzenia kosztu zakupu usługi. Wymaga jednak od klienta nakładów czasowych związanych z obróbką plików tekstowych i jest nacechowane pewnym ryzykiem.
Tak więc jeżeli masz czas na zabawę i nie straszne Ci są konsekwencje ewentualnych błędów wynikających z własnych pomyłek podczas sklejania ze sobą fragmentów tłumaczeń, to jest to rozwiązanie warte rozważenia.
Drugim aspektem, który poruszam w odpowiedzi, jest koszt oprogramowania CAT. Koszty platform wspomagających pracę biur tłumaczeń oraz sam przekład są na tyle wysokie, że gdyby każdy klient z osobna musiałby ponieść ten koszt, to wyszłyby nici z oszczędności.
Należy jednak jednoznacznie zaznaczyć, że w globalnym rozrachunku redukcja kosztów na przestrzeni długotrwałej współpracy danego klienta z jednym biurem tłumaczeń jest znacząca, co wykazałem w obliczeniach sporządzonych na potrzeby podlinkowanego powyżej wpisu o optymalizacji kosztów (przy spełnieniu kilku opisanych w nim kryteriów).
Tłumacz i jego punkt widzenia na analizę
Tłumacz z kolei chciałby otrzymać wynagrodzenie za całą objętość dokumentu niezależnie od występujących w treści repetitions, 101/100 matches oraz fuzzy matches. Przecież klient i tak nie wie, jak działa nasz soft, a nawet jak gdzieś coś słyszał o CATach, to pewnie myśli, że chodzi o koty.
Wnioskując z opowieści o poruszanych na grupach tłumaczeniowych wątkach i tematach, biura tłumaczeń to krwiożercy, którzy kasują swoich klientów za całą objętość dokumentu, a tłumaczom płacą tylko za faktycznie wykonaną pracę. I choć nie uczestniczę w tego typu dyskusjach, ponieważ w przeciwieństwie do ich uczestników nie mam na to czasu, to niestety wiele osób nadal ma takie wyobrażenie o pracy i zasadach działania biur tłumaczeń.
Nic bardziej mylnego, choć wynagrodzenie za realnie wykonaną pracę to faktycznie nasza podstawowa zasada. Współpracujący z nami tłumacze nie ponoszą żadnych kosztów związanych z zakupem oprogramowania CAT, a w większości przypadków jedyne, co jest im potrzebne do realizacji zleceń, to poza odpowiednimi umiejętnościami komputer z przeglądarką internetową podłączony do Internetu.
Nie ma również w tym aspekcie większej różnicy między tłumaczeniem technicznym, tłumaczeniem medycznym czy korektą tłumaczenia. Jeżeli pracę wykonuje algorytm, a nie zwoje mózgowe tłumacza, to dlaczego tłumacz miałby otrzymać za nią wynagrodzenie?
Choć prawda jest taka, że otrzymuje niewielkie wynagrodzenie również za tę niewykonaną pracę, ale trzeba wykazać się odrobiną uważności, aby to dostrzec.




